- Blog post • 10 min read
DevOps Principles: Flow, Standardization, Observability, and Secure Delivery
- Published on

DevOps Principles: Flow, Standardization, Observability, and Secure Delivery
For most of software history, development and operations existed as two separate entities. Developers wrote code and handed it off. Operations kept the systems running. Between them grew a widening feedback gap. Code moved forward through tickets and came back through incidents.
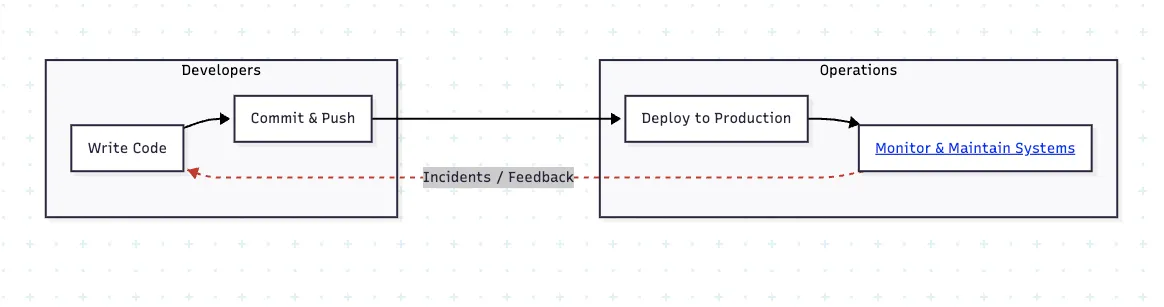
The real pain wasn’t in a single tool. It was in the delay. The longer it took for production feedback to reach the people writing code, the more expensive every mistake became. Distributed systems made this worse. A single release can touch dozens of services with different dependencies and failure modes. At that scale, slow feedback and inconsistent handoffs become unsustainable.
This problem helped drive the DevOps movement. Its core promise is simple: shorten the time between change and impact without increasing risk. When DevOps teams build and operate the same systems, accountability and insight align. The job shifts from merely deploying code to designing fast, reliable feedback loops.
This aligns with how DORA evaluates delivery performance. The 2024 DORA report highlights four delivery performance metrics that correlate with high performance:
- Lead time for changes
- Deployment frequency
- Change failure rate
- Time to restore service
Together, these metrics capture speed (lead time, deployment frequency) and reliability (change failure rate, time to restore). In other words, DevOps increases throughput while keeping risk measurable through consistent delivery and fast recovery.
So what does this look like in practice? DevOps work is making the path from commit to production repeatable and low-risk. In this article, we focus on three DevOps principles pillars: flow, standardization, observability, and secure delivery.
To improve, focus on principles you can apply across stacks. DevOps tooling changes. The underlying problems don’t: keeping delivery consistent, making systems observable, and shipping securely.
We’ll cover how flow shapes delivery speed, how standardization makes reliability repeatable, and how observability and secure delivery keep change safe at scale.
Flow
Software delivery behaves like a queueing system: when work piles up, feedback slows down. A few simple ideas explain why small batches, fast checks to test and deploy, and predictable pipelines outperform big, spiky releases.
Little’s Law: Too Much Work Slows Everything Down
One of the simplest and most universal equations in operations science is Little’s Law:
Lead time = Work in Progress ÷ Throughput
Translated into engineering terms: the more half-finished work sitting around, the longer it takes to ship anything.
In the software world, this takes place in the form of long-lived branches and half-reviewed pull requests. Even if every individual task seems manageable, the system slows because of merge conflicts and context switching.
A DevOps engineer learns to spot these queues. Shrinking them could mean automating pre-merge checks. Or tracking pull request aging as a signal of friction.
Consistency Beats Maxing Out Utilization
Queues blow up when pipelines run near capacity, especially when runtimes are unpredictable. The practical goal is headroom and consistency: keep builds fast, reduce variance, and avoid big merge spikes.
As utilization approaches 100%, even small fluctuations in workload cause massive delays. In CI/CD pipelines, this shows up as backed-up test queues and flaky jobs that spike runtimes. Design for headroom: parallelize where it matters, keep feedback fast, and reduce “everyone merges at 5 p.m.” spikes.
How This Shapes You as a DevOps Engineer
The laws above might seem like abstract ideas, but they’re the reason that DevOps practices work. What looks like DevOps culture (frequent merges, small changes, fast feedback) is really just queue management at scale.
This is the first DevOps principle in practice: treat delivery as a system with flow constraints. Stop seeing delivery as a sequence of tasks and start seeing it as a system of flow. The next challenge is scaling this across teams. That’s where standardization matters: one paved delivery path, shared defaults, and guardrails that keep changes safe without slowing teams down.
Standardization
Standardization makes delivery repeatable: one paved path, shared defaults, and fewer one-off pipelines. How can we make reliability repeatable across teams, projects, and environments? That is where platform thinking begins.
A good platform does not eliminate complexity. It abstracts it. Feature teams should not have to configure observability, manage rollouts, or define permissions from scratch. The platform should handle these through opinionated defaults that let every team ship safely without rebuilding the same systems.
There are a few principles that make this possible.
Treat the Platform Like a Product
A platform has users, and those users are engineers. Platform features should be discoverable and well-documented so that engineers can adopt them easily. The aim here is usability. We want to reduce cognitive load so that developers can focus on product work. When an engineer can build, deploy, and observe a service without extra steps, the platform is doing its job.
Like any product, the platform should have a feedback loop. If developers are avoiding the platform, that is a design issue.
Standardize the Delivery Flow
Reliability comes from consistency. Every team should follow the same delivery path. This is what enables continuous delivery at scale.
When each team builds custom scripts and pipelines, variance increases. A shared process helps eliminate those differences so that improvements can be validated.
Consolidate the Toolchain
Using multiple CI/CD tools for the same job can increase maintenance overhead and operational inconsistency, which can make reliability harder to manage. One reason is the added maintenance overhead of keeping multiple systems aligned, documented, and secure. Consolidation helps bring clarity.
Aiming to choose one CI engine, one deployment controller, and one infrastructure-as-code framework per environment class keeps systems straightforward. Every exception adds hidden costs. And when everyone builds on the same foundation, improvements like faster builds or better roll back logic benefit the whole organization.
Automate Policy
Manual review is still necessary in most cases, but we can limit what needs to be reviewed. Policy as Code and GitOps help add checks into the pipeline as continuous processes.
Policy tools such as OPA or Conftest enforce these standards automatically. Resources cannot be left untagged. Images cannot be unsigned. GitOps keeps runtime environments aligned with version-controlled definitions, so that we can roll back changes if needed.
In addition to static policy checks, many teams augment pipelines with automated, AI-assisted code review. These systems continuously analyze pull requests for security risks, dependency issues, misconfigurations, and policy violations, flagging problems and suggesting fixes before human review begins. When integrated into CI, automated reviews act as a consistent first line of enforcement, reducing review bottlenecks and ensuring baseline security and compliance issues are caught early so engineers can focus on higher-order design and reliability work.
Once delivery becomes consistent, the next focus is visibility. Observability connects every change to its real impact. This is the feedback loop that allows DevOps systems to keep improving.
Observability
Good observability starts with data that explains system behavior. The three core signals are:
- Logs: What happened.
- Metrics: How often and how much.
- Traces: Where and why latency or errors occur.
Each signal captures a different dimension of system behavior. Logs help during debugging, metrics expose trends, and traces show how this all works across services. DevOps engineers must ensure that every new service emits all three signals by default.
The standard solution is OpenTelemetry (OTel), an open framework for generating consistent logs, metrics, and traces across languages and backends. As of 2025, OTel’s tracing and metrics specifications are stable, and major vendors support ingestion natively.
With OpenTelemetry, you can often change telemetry backends with minimal instrumentation changes, mainly by updating exporters and configuration. It also standardizes your telemetry format across services, which simplifies correlating signals together.
Metrics should map directly to Service Level Objectives (SLOs). These are explicit definitions of what “healthy” means for users. For example, an SLO might target 99.9% of API requests under 300 ms or less than 0.1% error rate for a key endpoint. When a service exceeds its SLO, that is a sign to prioritize that fix.
A DevOps engineer’s goal is to make observability part of the delivery lifecycle. It should be instrumented at build time, verified in CI, and validated after deployment. Each release should prove its own health automatically.
Once systems can explain themselves, the next step is protecting them with the proper protocols in place.
Secure Delivery
Secure delivery follows the same principle as observability: it must be built in. The goal is to make the safe path the default, enforced through the pipeline. This is the core of shift left security. It is the responsibility of a DevOps engineer to make security part of the development process itself.
The first layer is secrets management. Credentials should never be hardcoded in code or checked into config files. In CI, store secrets in an encrypted secrets store (or fetch from a secrets manager) rather than plaintext env vars.
Every secret should be stored in a centralized manager (such as Infisical) and fetched dynamically at runtime. Pipelines should fail if plaintext credentials are detected, and access should be scoped to the service, not the user. This eliminates a large portion of accidental exposure risk.
The next layer is artifact integrity. Every build should produce a verifiable artifact (i.e., container images, binaries) with a digital signature attached. Tools like Cosign or Sigstore make this straightforward. Signed artifacts prove origin and protect against tampering during deployment. Verification should happen automatically in the CI/CD pipeline before rollout.
Security also depends on consistent policy enforcement. Rules should exist as code, in a centralized location. Policy tools like OPA plus Conftest can check Terraform plans, Kubernetes manifests, and container configs before merge. Separately, authorization frameworks help enforce access rules inside applications.
Finally, environment drift should be monitored continuously. Infrastructure and configuration should always match what’s declared in version control. When a change happens outside that process, the system should flag it automatically.
Putting DevOps Principles into Practice
DevOps is best understood as a way of thinking about how change moves through a system, and how to make that movement safe and sustainable. While these principles remain foundational in 2026, the role applying them has evolved as software systems scale and AI tooling automates large parts of the development lifecycle.
The focus has shifted from individual developer productivity to centrally managed platforms. Through internal developer platforms, platform engineers encode DevOps principles into shared infrastructure, applying them consistently across the organization rather than service by service.
These principles work together. Flow is the foundation. Standardization makes it repeatable. Observability makes it measurable. Secure delivery makes it safe.
That begins with small, reversible changes. Smaller merges, automated checks, and clear rollback paths keep systems moving without being bogged down by incident tickets. The goal is to shorten the distance between change and feedback until continuous improvement becomes the default.
Sustainability extends the same logic to cost and operations. Spend should follow meaningful work, and systems should scale to meet demand and contract when not needed.
When these principles are working, delivery becomes boring in the best way: fewer surprises, faster recovery, and steadier output.
